前言
手上有部老ipadmini2,放着吃灰不好,就拿来做看书看漫画专用机。
哔哩哔哩漫画乘着活动充了50元,但还是不够划算,继续充钱有点亏,就研究了几个开源漫画软件。
目前我看下来ios上其实比较好的是源阅读,但是ipadmini2系统只到ios12.5,源阅读最低要求ios13,恶心人。
香色闺阁非常友好的支持了我的mini2,所以我现在主力漫画软件就是香色闺阁。
但是香色闺阁的xbs加密源文件属实也是恶心人,只能用ios设备编辑,不能在电脑上编写,好在本身很简单,原理就是个简易版爬虫。
从一次实战开始
最近喜欢看英文版日漫,边娱乐边复习六级(属于是给看漫画找借口了)
但是已有的香色闺阁漫画源中英文书源较少,所以打算自己写一个
选的网站是bato.to,一个资源非常全,而且可以大陆直连的网站
新建站点
进入香色闺阁软件,点击左面的站点管理,点击更多,选择新建站点
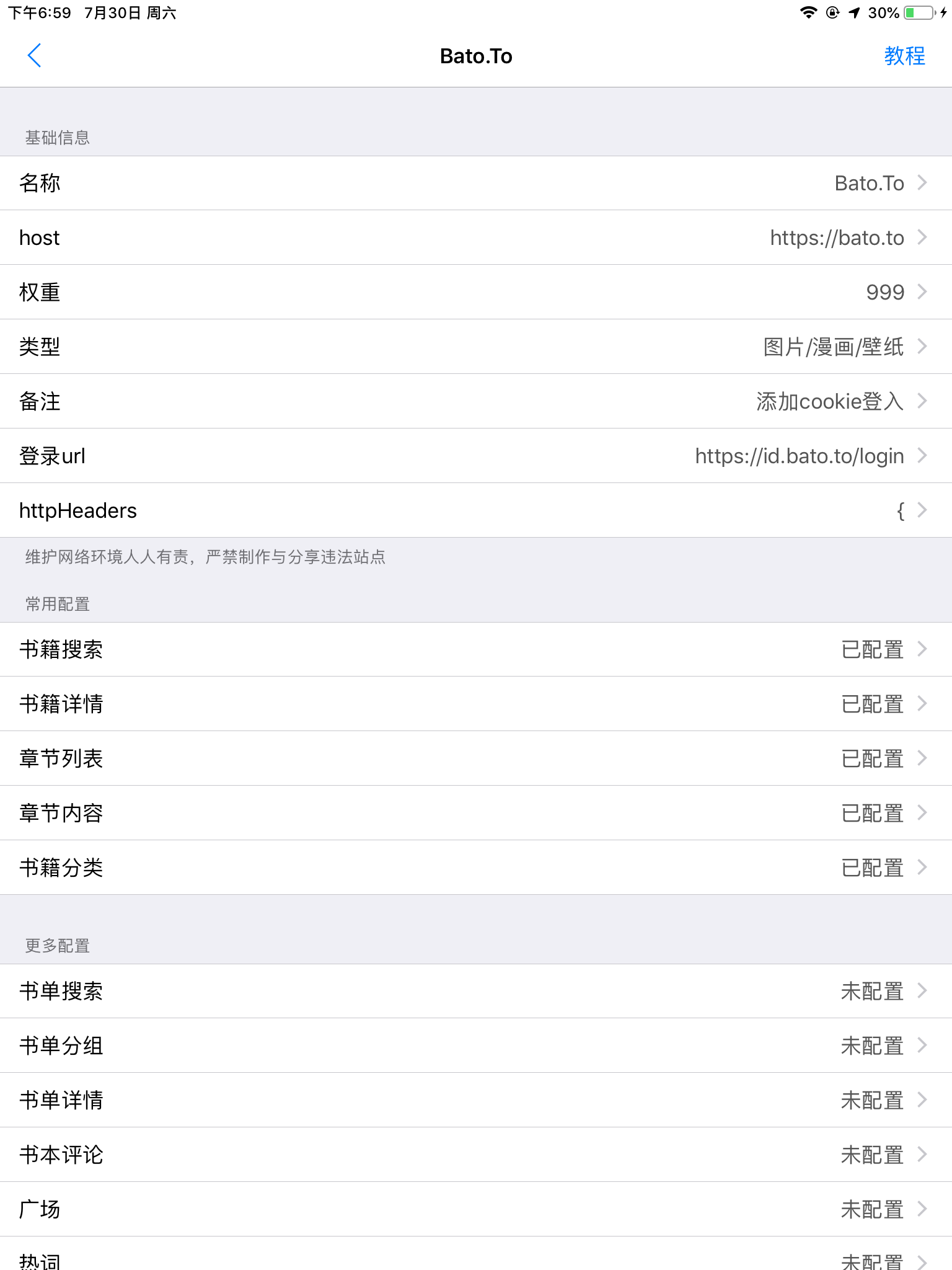
这里我已经把基础内容填写完成了
大部分选项的含义和作用都是一目了然的,这里只挑几个重点讲一下
“权重”:该站点在列表中排列的先后顺序,最大值9999,不过好几个源作者都喜欢标9999,而且xbs还加密(说的就是你益达源),总体上没什么用,你编辑站点的时候可以直接顶置,方便反复修改
“httpheaders”:cookie装里面,有些站点可能要登入才能查看某些资源,cookie的获取方式可以直接百度
一个示例:
{"Cookie":"XXX","User-Agent":"Mozilla\/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit\/537.36 (KHTML, like Gecko) Chrome\/96.0.4664.110 Safari\/537.36"}
常用配置部分
书籍搜索
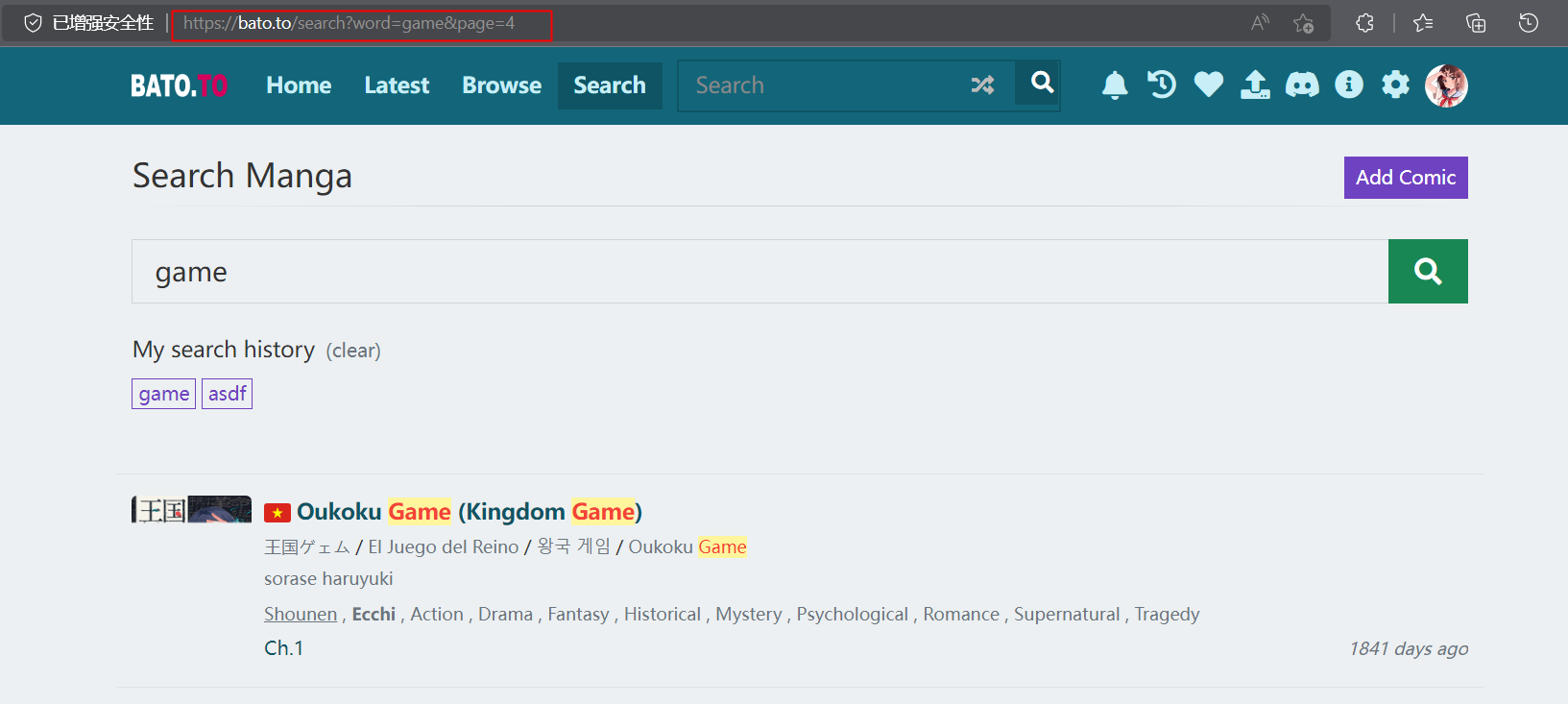
进入你的目标网站,搜索某个很常见的关键词,保证有多页结果,然后翻到比如第4页,记住上面的连接格式
https://bato.to/search?word=game&page=4
修改为下面这种格式:
https://bato.to/search?word=%@keyWord&page=%@pageIndex

响应规则里面按照格式填写,具体的div,class之类的通过F12打开目标网页源文件查看
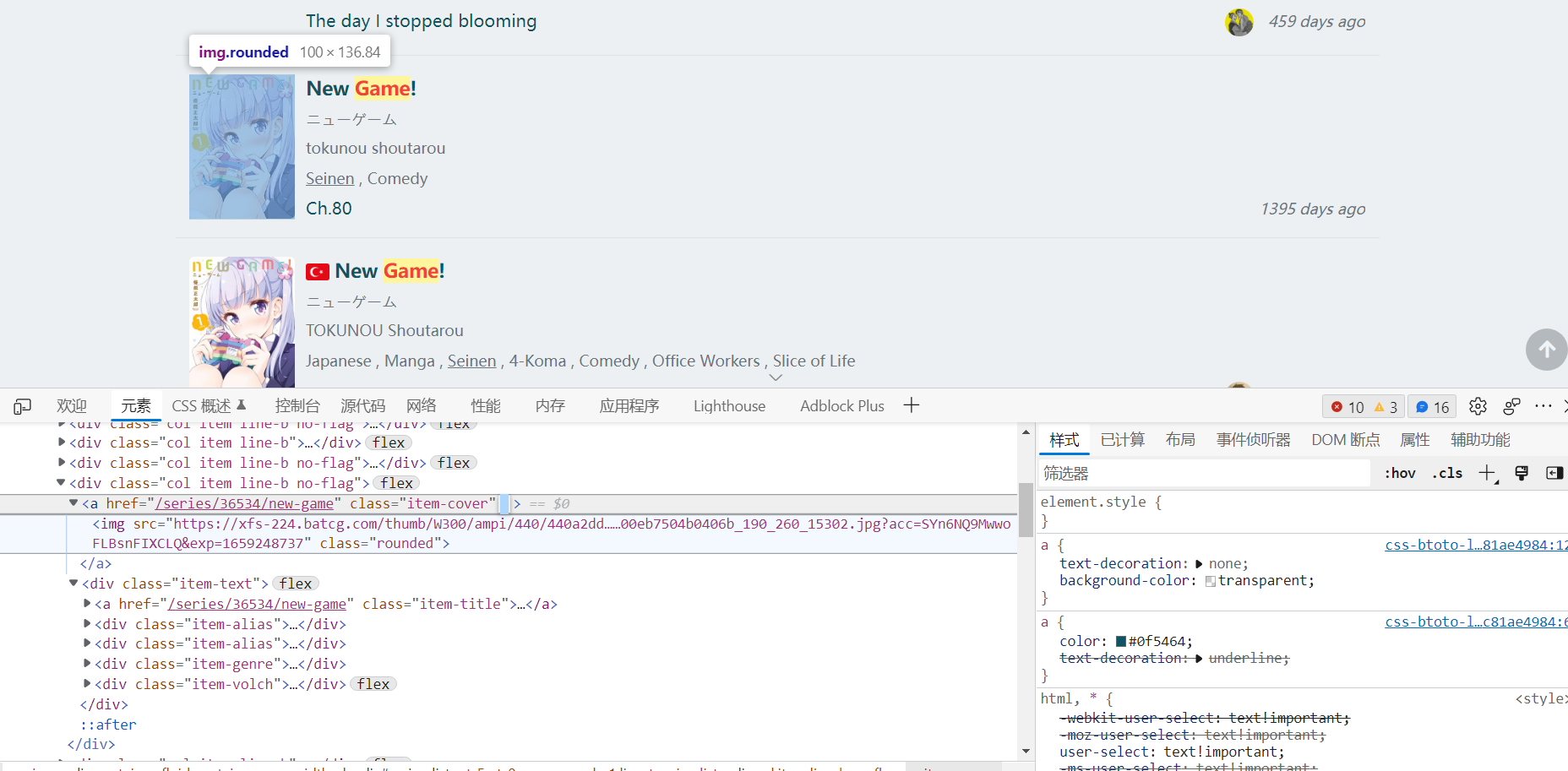
格式很简单
// 开头
div或img之类的对应<div >, <img >
@ 用来定位class或者id
要获取<div src="xxx">里面的src时也是用@src
“更多配置”这一块,在制作小说源的时候要调一下编码为中文编码,我们这里是漫画,不用管文本编码
书籍详情
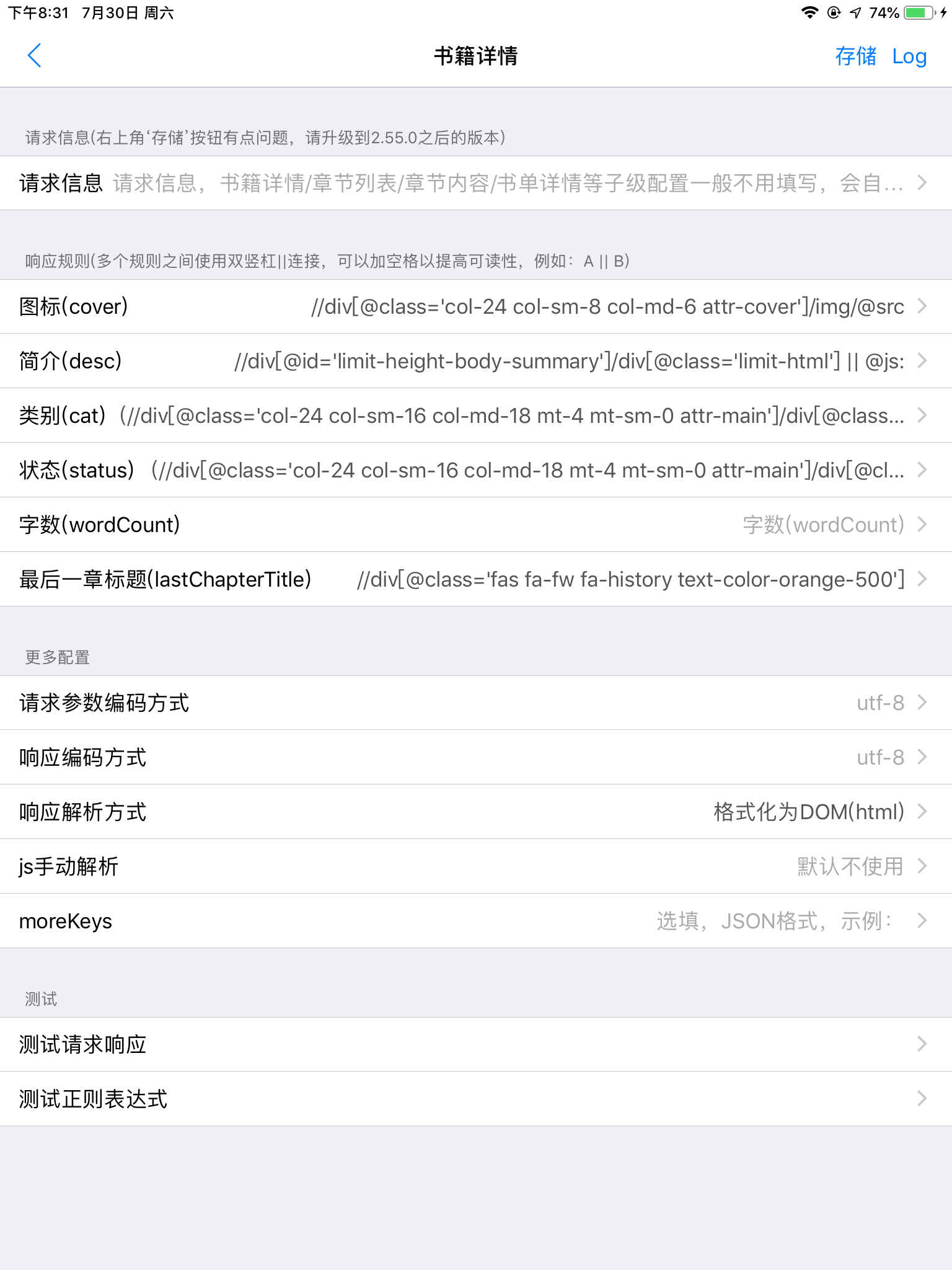
详情这一块,接触文本会比较多一点,可能需要借助js格式化一些段落,或去除一些无用标记
这里举个例子,可以参考一下(去除多余的网页br格式)
//div[@id='limit-height-body-summary']/div[@class='limit-html'] || @js:
let reg = new RegExp('<br />', 'g')
return result.replace(reg, '')
章节列表
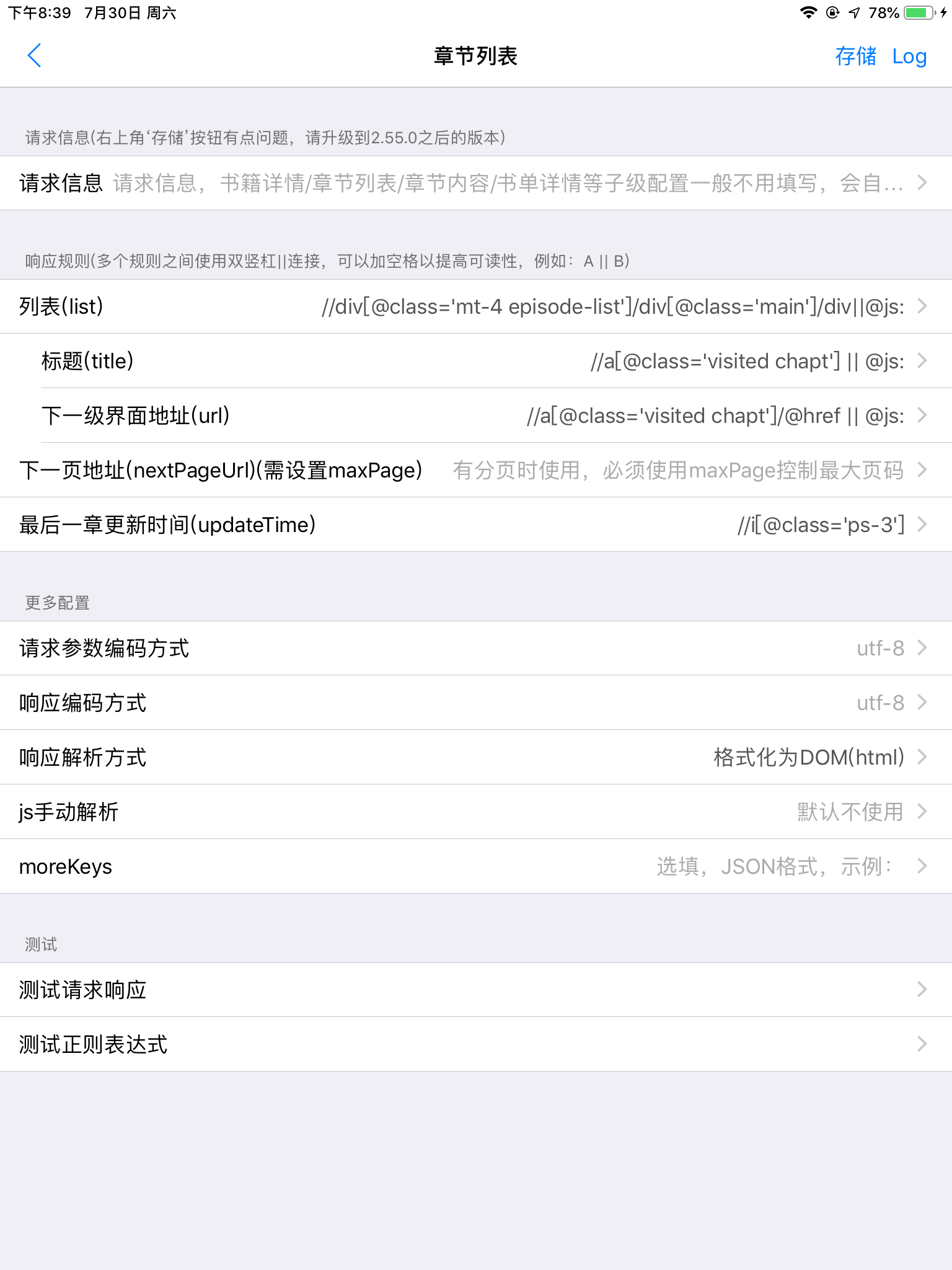
这里的“下一级界面地址”要注意,可能会有坑
我这里的bato.to网站就遇到坑了
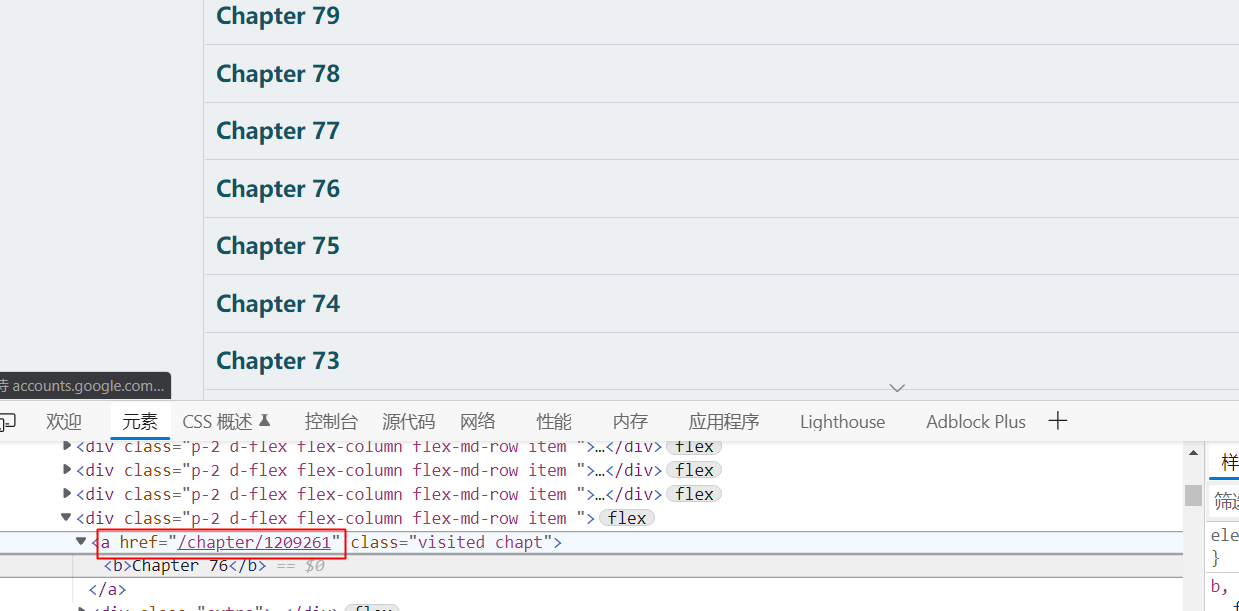
bato.to网站的章节链接不是完整URL,而是相对网站主域名的相对路径,直接使用就会 “ URL错误,没有URL编码? “ 这样报错
手动调整一下,保证是完整的URL传出:
//a[@class='visited chapt']/@href || @js:
let url = 'http://bato.to' +result;
return url;
章节内容
章节内容就是我们最关键的漫画图片部分
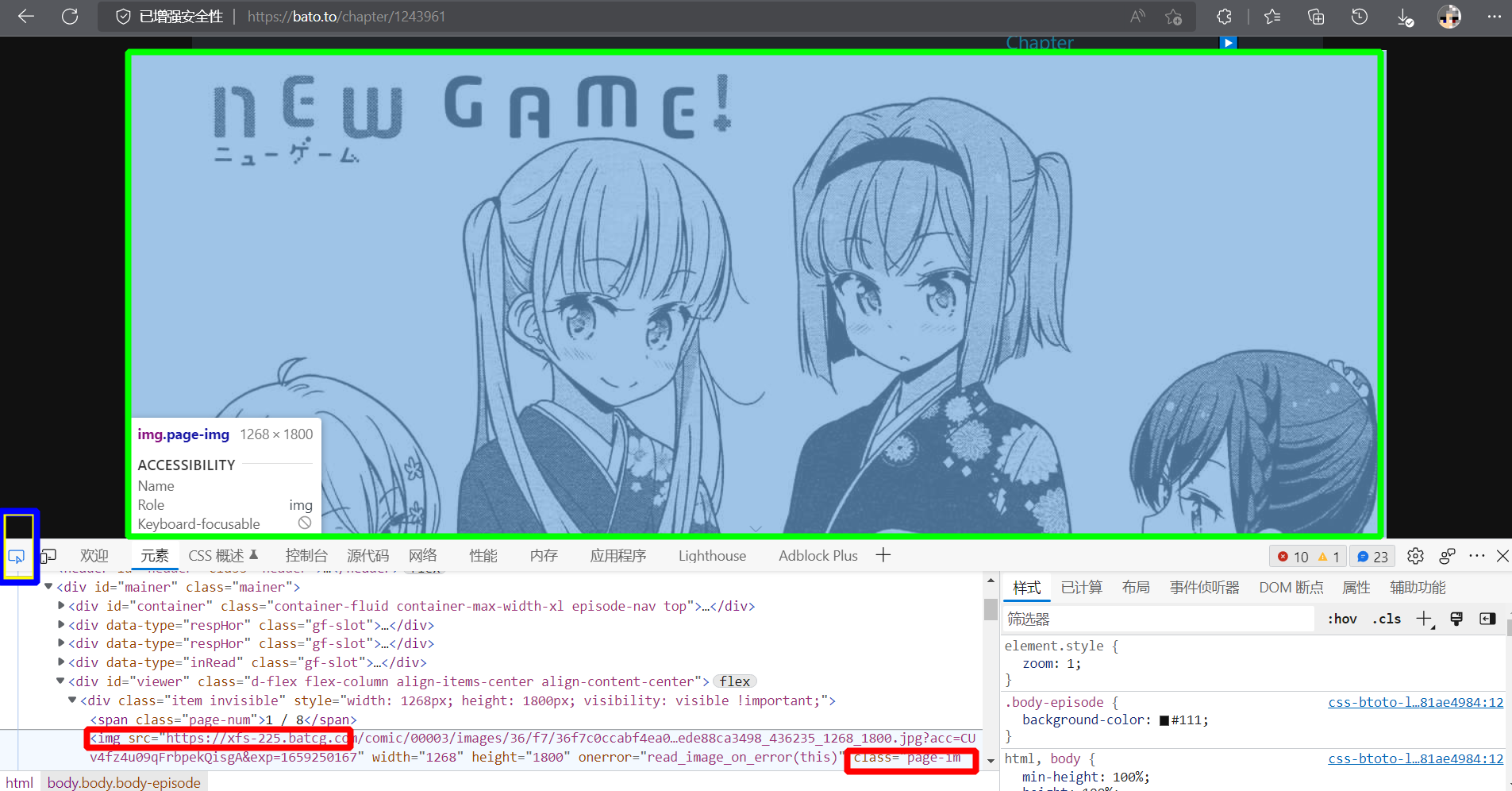
使用“蓝色框框”中的元素检查工具,点击“绿色宽宽”中的也就是漫画图片部分,然后下方开发者工具就会跳转出来相应的源码部分
我们关注两个“红色框框”中的内容,src是我们漫画图片的直接地址,class用来定位这个部分,辅助我们得到src
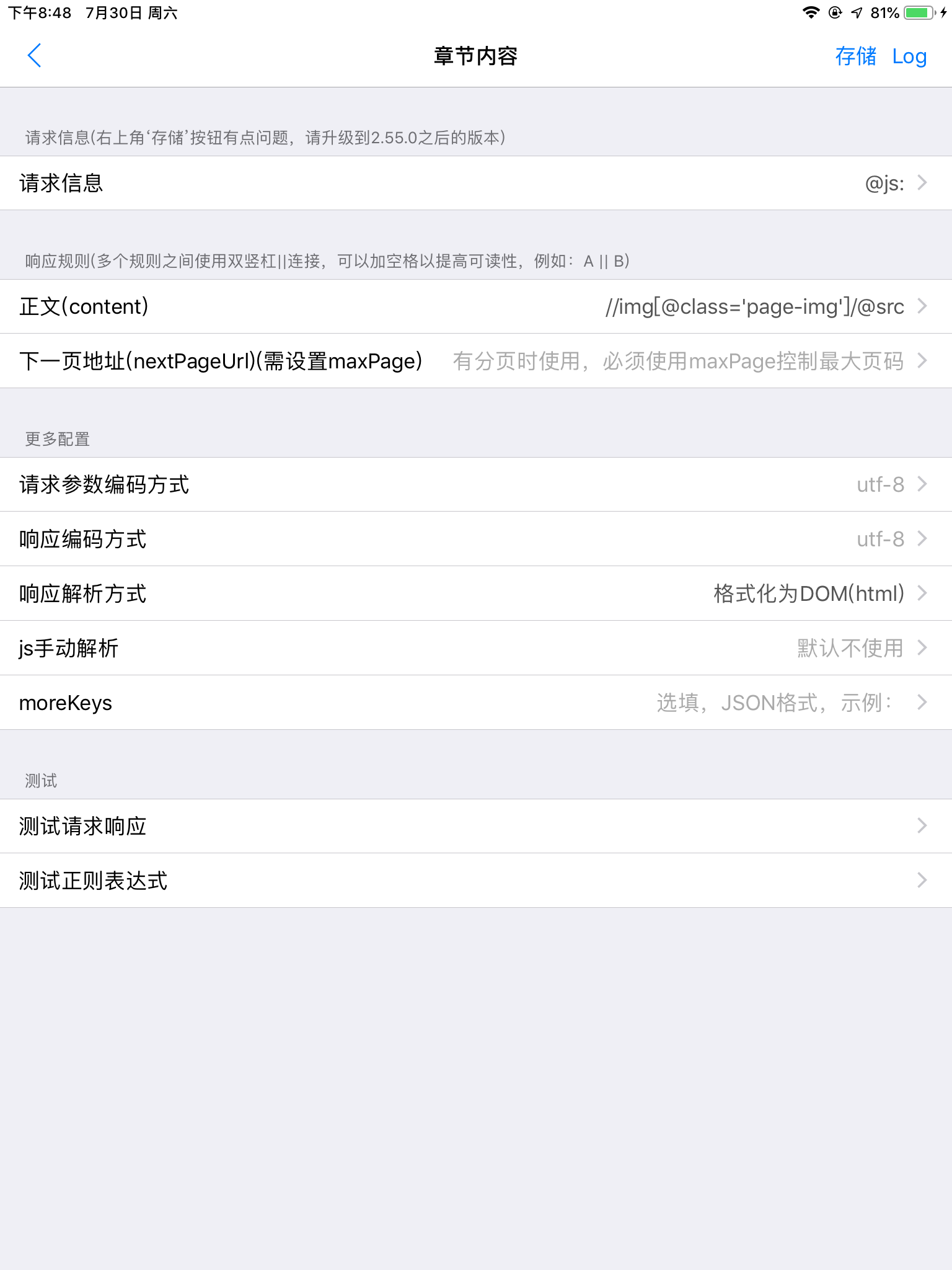
这个网站还有个坑,漫画图片加载是js动态加载,直接爬取网页得不到图片
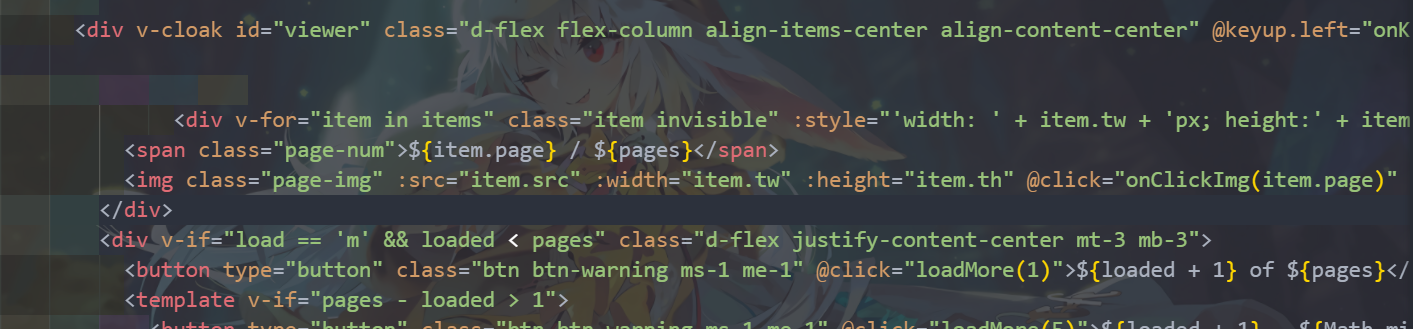
这里请求信息我们要加上webView
(这类js加载的网站第一次打开某本漫画会比较慢,要加载完全部资源才会在软件上显示出页码)
请求信息:
@js:
return {'url':result, 'webView':""};
之后正文部分还是一样的
正文:
//img[@class='page-img']/@src
书籍分类
整体还是大同小异,不过这一部分要手动配置的内容比较多,我就直接上截图和代码了
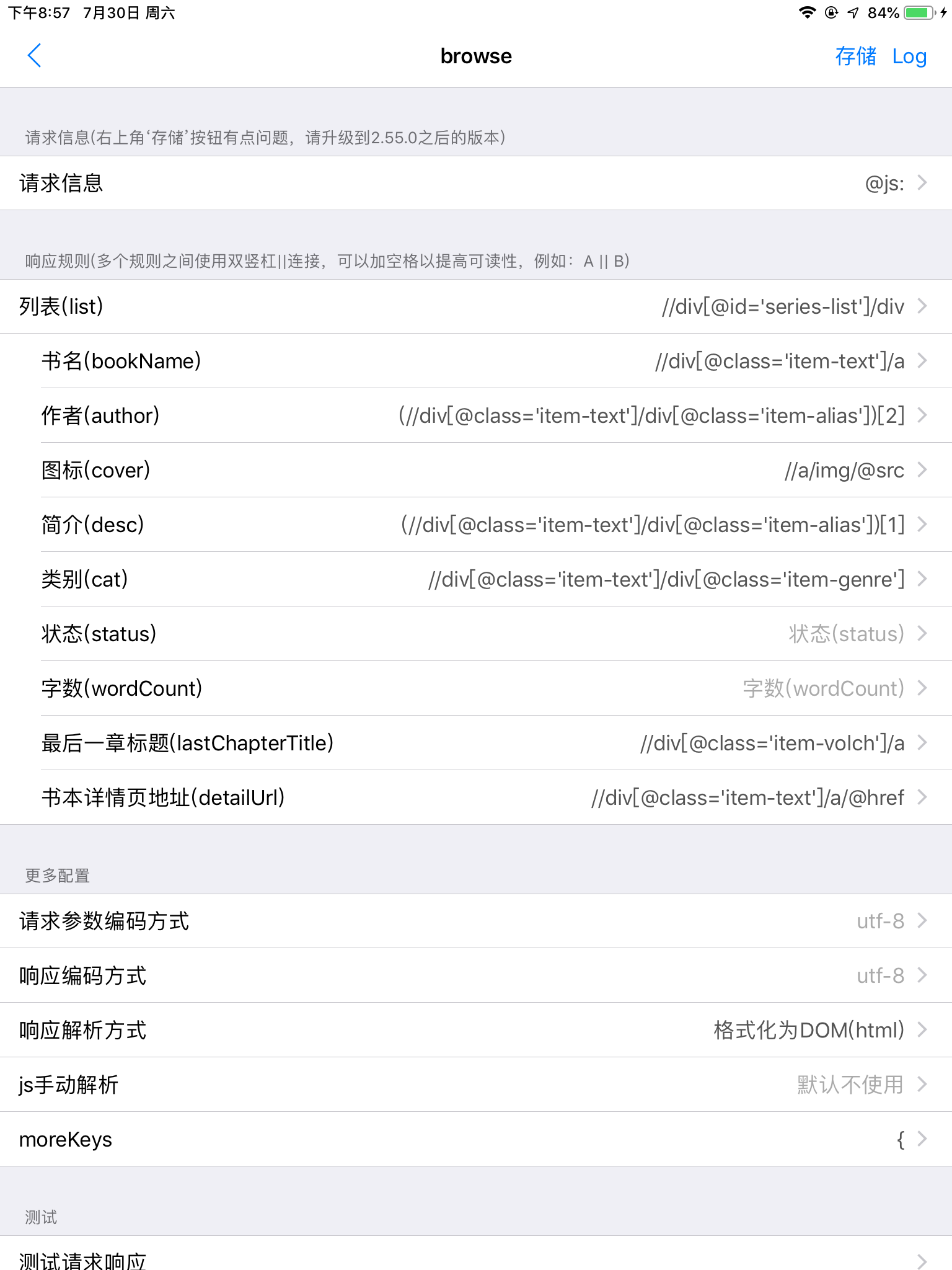
请求信息:
@js:
return 'https://bato.to/browse?genres=' + params.filters.genre1 + ',' + params.filters.genre2 + ',' + params.filters.genre3 + ',' + params.filters.genre4 + '&langs=' + params.filters.translated + '&origs=' + params.filters.original + '&release=' + params.filters.release + '&chapters=' + params.filters.chapters + '&sort=' + params.filters.sort + '&page=' + params.pageIndex;
更多配置-moreKeys:(全是标签)
{"pageSize":60,"requestFilters":[{"items":[{"value":"","title":"All"},{"value":"artbook","title":"Artbook"},{"value":"cartoon","title":"Cartoon"},{"value":"comic","title":"Comic"},{"value":"doujinshi","title":"Doujinshi"}
。。。。。。
{"value":"zombies","title":"Zombies"}],"key":"genre4"},{"items":[{"title":"All","value":""},{"title":"ar","value":"ar"},{"title":"en","value":"en"},{"title":"es","value":"es"},{"title":"pt","value":"pt"},{"title":"it","value":"it"},{"title":"pl","value":"pl"},{"title":"id","value":"id"},
。。。。。。
{"title":"Pending","value":"pending"},{"title":"Ongoing","value":"ongoing"},{"title":"Completed","value":"completed"},{"title":"Hiatus","value":"hiatus"},{"value":"50","title":"50+"},{"value":"10","title":"10+"},{"value":"1","title":"1+"}],"key":"chapters"},{"items":
。。。。。。
{"value":"views_w.za","title":"7days"},{"value":"views_d.za","title":"24hours"},{"value":"views_h.za","title":"60minutes"}],"key":"sort"}]}
更多配置
比如书单啊,广场啊,热词啥的,因为不是必须品,我这里就不继续写教程了
想做的话和上面的例子都是大同小异,按照格式制作即可
Bato.to.xbs
还有不懂的地方可以下载这个样例xbs
xiangseguige/书源 at main · UFOAlastor/xiangseguige (github.com)