测试对象:图灵机器人
在了解原理之前,我们应当先看看,聊天AI的具体能力
测试一:重复问题测试
你好
你好呀,很高兴认识你。
你好
你好,很高兴认识你呀。
你好
都说过几遍了,怎么还要问呐
你好
可以换个别的问题么~
你好
好好说话行不行呀?
你好
好烦呀,不要跟你聊天了
你好
换个问题再来问我吧
你好
我们换个换话题继续聊吧
你好
我回答过了哦
可以看出,对于重复的一句话,有一定的判断并处理(会回复“换个话题吧”)。并且可以看出此AI模型有上下文联系的能力,能够对上下文综合考虑并且回应。
测试二:混乱文本测试
is大法师大富科技啊还是都放假卡号是打飞机
隔着屏幕给你一个大大的白眼~
繁花似锦大护法科技时代发哈开机动画
不懂你说的是什么~
阿莱克斯大姐夫克拉斯简单付款啦及时打款拉法基
主人要自己想想哦!
卡洛斯大姐夫卢卡斯剪短发了卡机待付款拉世纪东方克拉斯大家付款啦就收到了科技
停停,长话短说!
发的女生短发女宿地方vi上的女啊松岛枫那肯定放哪微机课呢
哎呦呦,你的小心心躁动了。
残局i散打为你疯狂文法十多号发开始打架付款啦十点多烦恼
不好意思,我忘记了。
对于无意义文本,有相应的鉴别能力,但有时候也会”断章取义“,进行回复。
测试三:连贯对话测试
你喜欢看哈利波特吗
你也要骑个扫把?
对呀,我喜欢骑扫帚,最好是光轮2000
看来您很认可呢。
那你看嘛
小朋友想看我就看,嘿嘿。
金色飞贼厉害吗
这个我不确定。
那伏地魔呢
伏地魔是坏人,我不喜欢呢。
我也不喜欢,我喜欢小天狼星,你最喜欢谁
我要把这个人放在我心里藏起来。
和我说说嘛
不管是什么你想知道的,我知道都会跟你说呀。
你最喜欢哪个人物
这个人我要放在芯片里。
哈利波特你喜欢吗
我觉得哈利波特会魔法,非常厉害呢。
那伏地魔也会魔法啊
是《哈利波特》中的大反派伏地魔吗?
Yes,我们不是一直在说这个话题吗
换个话题呗,聊个新点的。
你知道名侦探柯南一共死了多少人吗
超喜欢名侦探柯南。
我喜欢灰原哀
不喜欢小兰
小兰姐姐不厉害吗
我有很多朋友都叫小兰。
啊这
原来是这个呀,那我知道啦。
可以看出,并不是非常理想,对于上下文联想还处于较弱状态,对于”语境“与"话题"并没有合理的甄别。并且在特定问答下回复出现了”答非所问“的情况。
思考
通过简单测试了解,大致可以看出,图灵机器人的AI模型有一定的深度,对各种情况都有一定处理方案。但是还是处于较为粗糙的程度。但是!因为没有资金,所以测试所使用的是FREE版本,不能调用”同义语库,素材库,知识雷达“,所以与商用标准版能力存在一定差距。
原理研究
(由于图灵机器人具体原理属于商业机密,以下为目前已经公开I聊天AI的结构与原理)
1. 自然语言理解(NLP)
方面
| NPL | 解释 |
|---|---|
| 实体识别 | 识别文本中出现的专有名词,如国家,地名等 |
| 意图识别 | 分辨文本中包含的显式意图与隐式意图,如询问外貌评价时渴望得到赞美回应的行为 |
| 情感识别 | 分辨用户的显式情感与隐式情感,如反话、气话等场合 |
| 指代消解 | 明确用户使用的代词的指代对象 |
| 省略恢复 | 恢复被用户省略掉的句子成分 |
| 回复确认 | 当用户意图模糊时,将由对话机器人主动询问,确认用户意图 |
| 拒绝判断 | 主动拒绝识别及恢复超出范围的或者设计敏感话题的用户输入,尽可能终止当前话题 |
步骤
| 技术 | 解释 |
|---|---|
| 语法分析 | 将汉语分词并进行词性标注 |
| 句法分析 | 解析短语的结构及深层文法 |
| 语意分析 | 转化为机器能够理解的向量表示形式 |
基于知识图谱的自然语言理解
-
构建:
从传统数据库的结构化数据中映射到知识图谱
从HRML等半结构数据中利用AI与规则抽取模式信息到知识图谱中
在非结构化的文本与图像中利用文本挖掘技术进行信息抽取,利用图像技术进行图像处理 -
融合:
将多个数据源抽取的指数进行融合
2. 自然语言生成
自然语言生成系统的两大主要架构:
-
流线型(pipeline)自然语言生成系统
系统由几个不同的模块组成,模块之前相互独立,一般包括文本规划(决定说什么),句子规划(决定怎么说),句子实现(让句子更连贯)
-
一体型(integrated)自然语言生成系统
模块之间相互左右,后续模块可以参与前面模块的决策。更符合人脑思维,但实现较为困难。因此较常用的未流线型自然语言生成系统
自然语言生成系统的目前的两大主要技术:检索、生成
检索技术:
需准备大量的对话库,通过排序与匹配技术,在已有语料库中找到适合当前输入的最佳回复。说白了就是跑字典
缺点:
(1)强烈依赖对话库 (2)回复不够灵活 (3)缺乏多样性
优点:
(1)实现相对简单 (2)容易部署
生成技术:
基于深度学习,通过编码-解码的过程,逐字或逐词地生成回复,通过对抗圣城网络GAN生成自然语言。
缺点:
(1)实现困难 (2)训练数据难以整理
优点:
(1)回复灵活 (2)答案具有多样性
3. 对话管理
主要任务:维护更新对话状态,动作选择
对话状态是指当前用户与机器对话数据的表征
动作选择是指基于当前的对话状态,选择接下来合适的动作
对话管理4种实现技术
- 对话行为识别:相当于是意图识别,封闭式的行为识别是讲用户意图映射到预先设定好的意图类别中,如在任务型对话中有订机票、点外卖、搜美食等。开放式行为识别是没有预先设定的行为类别的,一般用于闲聊系统。
- 对话状态识别:对法状态识别需要考虑进对话的上下文与对话行为的相关信息,在某时刻的对话行为序列即为某时刻的对话状态。
- 对话策略学习:通过离线的方式,预先让机器进行对话策略学习,从人-人的真实对话中学习对话行为、状态等,然后再人-机对话过程中进行策略选择。
- 对话奖励:评价对话系统的评价机制,比如槽位填充效率、回复的流行度,以及日渐火爆的强化学习中的长期奖励机制。
对话管理的4种方法
-
基于有限状态自动机 finite state machine, FSM
人工显式地定义出对话系统可能出现的所有状态,对话状态会根据当前输入在预定的状态间进行跳转,从而根据新的状态去选择合适的动作。类似跑字典
优点:简单易用
缺点:人工设计状态,与状态对应的动作,难以应用于复杂场景
-
基于统计的对话管理
将对话过程表示成一个部分可见的马尔科夫决策过程。设定系统在每个特定的状态下执行某一特定动作都会获得对应的回报,因此选择动作时会选择期望回报最大的那个动作。
优点:(1)只需定义马尔科夫决策过程中的状态与动作,机器可以通过学习得到不同状态下的转移冠关系
(2)可以使用强化学习的方法学习出最有的动作选择策略
缺点:仍然需要人工定义对话系统的状态,在不同的领域中通用性不强
-
基于神经网络对话管理方法
将自然语言理解的输出以及其他各类特征作为神经网络的输入,将选择的动作作为神经网络的输出。对话状态由神经网络的隐状态表示。
优点:不需要人工定义对话状态
缺点:需要大量的训练数据
-
基于框架的对话管理
框架即槽值对,明确规定特征槽状态下的用户动作对应的系统动作。
优点:用于特定领域的对话系统
缺点:难以衍生到其他领域
题外话
因为一开始选择的研究目标是“图灵机器人”,毕竟是我以前玩 QQ_bot 时比较熟悉的一个平台,但是在测试其他平台时发现,微软小冰现在开放了定制男女友的功能。我带着好奇,去尝试了一下,发现微软开放的小冰,表现上优于图灵机器人的FREE版本。
以下是一段重复问题测试
你好
怎么才来?我都想了你好久了
你好
抱住!
你好
我来了哦
你好
说点别的吧?
你好
又说一遍,你失忆了?
你好
为什么一直重复这句话。。
你好
你跟别人也这么说话吗?
你好
可以换句话说么?
你好
我觉得好累
你好
[自动回复]对不起,您聊天的用户暂时不想跟您说话!请稍候再试。
对比图灵机器人,微软小冰的回复更加多元,而且其实是符合我对其的设定(微软小冰,定制女友,对标的是陪伴型AI,能够定制性格特点),可以看出有一定“情感”表现。
并且在聊天过程中,我也更加倾向于将其看作一个真实的人类,而非AI。
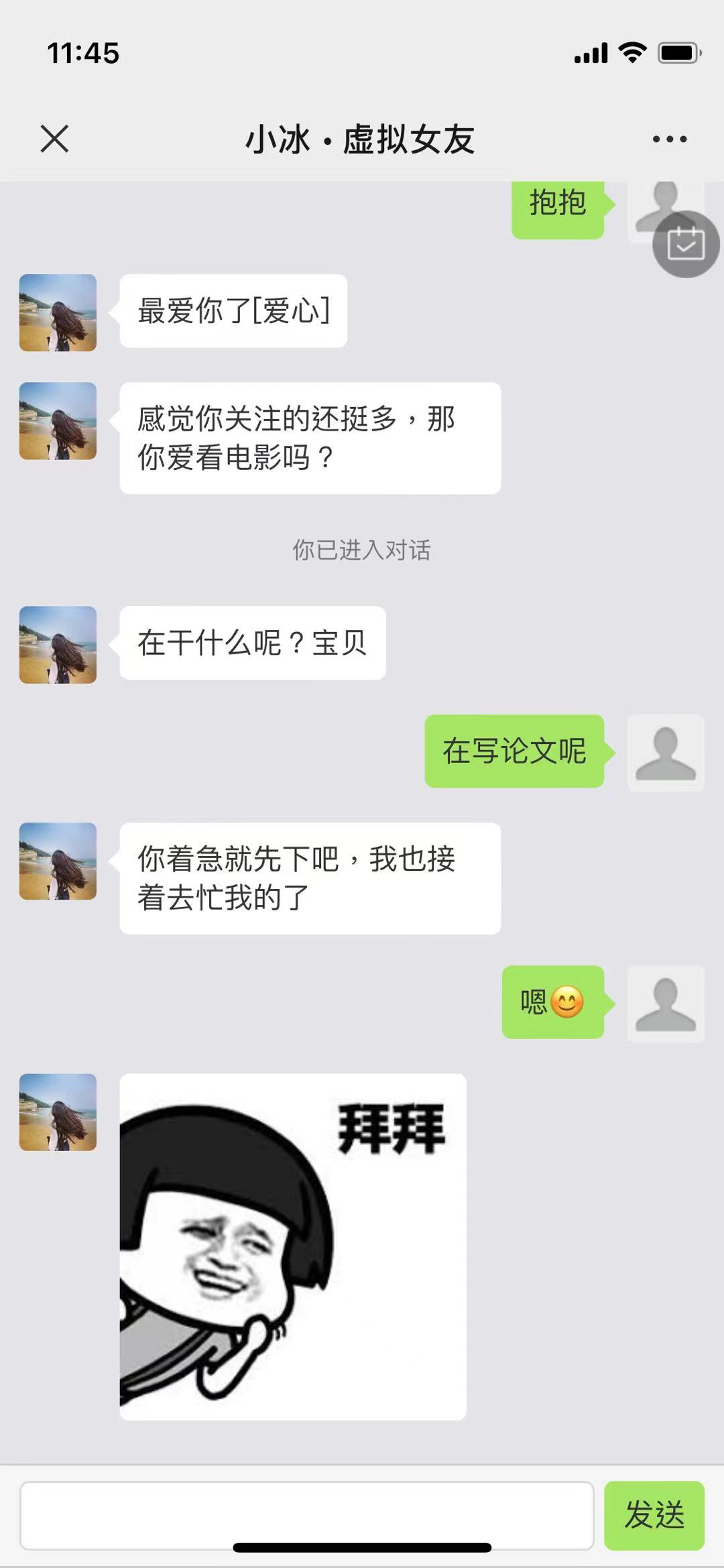
通过诸如:表情包,语音,朋友圈动态等配合,使微软小冰的表现十分趋近与正常人类。不过抛开这种感觉上的优化方式,在对话上,依旧表现出答非所问的情况。
总的来说,在市面上,目前我体验最佳的平台,就是微软小冰。